
查詢引擎百百種為何選中了 Trino 搭配 Iceberg 的組合呢?在先前的系列文《從倉儲到湖倉,初探Trino》中提到了 Trino 的好處,與 S3 結合便可發揮一加一大於二的效果:
這邊筆者想針對 S3 為什麼對於 Iceberg 來說是好的儲存層選擇,做多一點的展開,以補足前篇僅對選用 Iceberg 的理由做闡述的不足:
read-after-write 實現資料一致性,有利於 Iceberg 對於 ACID 的支援。99.999999999% 持久性,透過異地備援、資料副本等實現,資料穩定性極高。$0.023/GB/mon 的收費遠低於傳統雲端儲存 (EBS、EFS) 數倍。*read-after-write:寫入成功後馬上就可以讀到最新內容,不會讀到舊的或不存在的版本;
相較於最終一致性(eventual consistency)保證可能發生寫入延遲,這樣的機制擁有更強的資料一致性。
正所謂工欲善其事,必先利其器,必須了解你的工具才能戰無不勝,要了解 Iceberg 就必須知道 Trino 對其進行查詢時背後的機制:
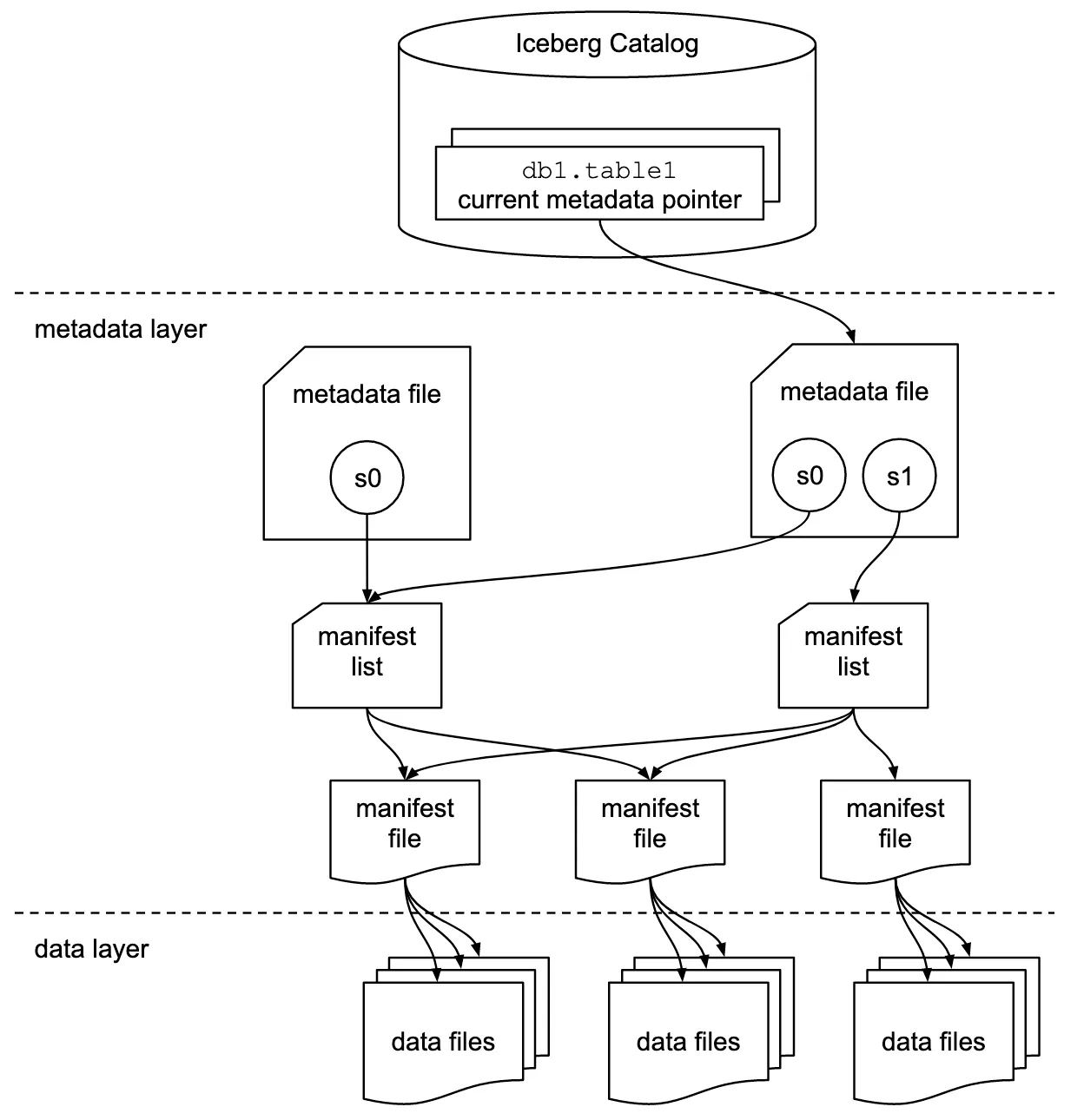
從上圖可知,當使用者在 Trino 下了一段語法後,取得真正的data file前會先讀取 metadata,再透過 metadata 取得查詢所需之 snapshot ,而後下載所需之 manifest ,最後才能取回查詢所需之資料。
根據官方文檔記載:
Since Iceberg stores the paths to data files in the metadata files, it only consults the underlying file system for files that must be read.
當 Trino 查詢 Iceberg table 時,只有在訪問「必要的檔案」時會向檔案系統 ( S3 ) 發送請求,也就是說讀取以下存於 S3 之檔案:
metadata files
manifest lists
manifest files
data files
之時都需要對 S3 API 做請求以取得這些檔案,而對於 Trino Cluster 來說,多讀一次便是多增加一次 S3 I/O 的成本,這樣隱含著可能發生以下問題:
那該怎麼追蹤 Trino 查詢讀取了多少「必要檔案」呢?
細看 Trino 對 Iceberg 的查詢結果都會顯示如: Splits: xx total 之訊息,代表著查詢產生了多少個 Split 任務。
## Trino query Iceberg example
trino> select * from iceberg.datalakehouse_silver_production.{table};
...
Query 20250717_072827_00273_dqcau, FINISHED, 2 nodes
Splits: 34 total, 34 done (100.00%)
9.67 [1 rows, 31.2KB] [0 rows/s, 3.23KB/s]
Split 為 Trino 中的「最小工作單位」,每個 Split 對應到的是一段 data file ( 通常是 parquet file,或其中的一部分 )。
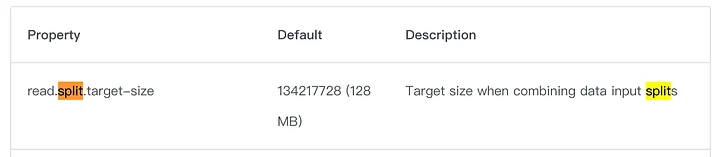
而根據官方文檔所述 (如下圖),一個 Split 大小 default 是 128 MB ,Trino 會依檔案大小與 layout 決定產出多少 Splits。
系列文明日《冰山不止一角,Iceberg 與 S3 (四)》,在理解了 Iceberg 資料讀取的奧秘後,聰明的讀者大概已經隱約察覺到問題所在。
沒錯,明日我們將揭開 Iceberg 潛藏的效能挑戰,以及背後可能帶來的成本問題。
My Linkedin: https://www.linkedin.com/in/benny0624/
My Medium: https://hndsmhsu.medium.com/


 iThome鐵人賽
iThome鐵人賽